Outils d'utilisateurs
Table des matières
https://github.com/SanderMertens/ecs-faq
L'Entity Component System - Qu'est ce que c'est et comment bien s'en servir ?
Introduction
Ce tutoriel a été commencé pour le site Zeste de savoir, à l'initiative de valent20000, qui souhaitait écrire un tutoriel sur l'ECS en C++ avec Anax. Au final, comme j'ai écrit la majorité de ce tutoriel, mais que je n'ai pas le temps pour le moment de le finir, je le publie ici, dans l'état. J’essaierais de le compléter, un jour…
Lorsque l'on commence un nouveau jeu, on n'est pas confronté en général au syndrome de la page blanche. Au contraire, on a souvent beaucoup d'idées sur ce que le jeu contiendra, sur des éléments de gameplay, sur ce qui composera le jeu. Il faut même parfois mettre de côté des idées, partir petit et ajouter progressivement des éléments à son jeu.
Par contre, lorsque l'on commence à entrer dans le code du jeu, on est parfois perdu. Quels sont éléments à créer pour concevoir un jeu ? Comment ces éléments interagissent ? Comment éviter de devoir recommencer son jeu plusieurs fois parce que l'on a fait de mauvais choix ?
Il ne faut pas se faire d'illusions, créer un jeu est une tâche très complexe et très longue. Les blogs relatant les mauvaises expériences sont nombreuses (lire en particulier la série d'articles Erreurs classiques des créateurs de jeux vidéo amateurs.
Un moteur de jeux est quelque chose de complexe en soi. La meilleure approche pour créer un jeu est d'utiliser un moteur de jeux existant, qui vous propose déjà une architecture prête à l'utilisation. Il en existe plusieurs moteurs de jeux gratuits, très bons pour débuter et pour aller plus loin. Si votre objectif est la création d'un jeu, c'est cette approche qu'il vous faut suivre. Ne rejetez surtout pas les moteurs de jeux existants pour de mauvaises raisons, comme “je veux tout créer moi même pour avoir plus de liberté”. En pratique, si vous faites cela, vous passerez plus de temps à régler les problèmes d'implémentation de votre moteur de jeux plutôt que de réellement concevoir votre jeu.
Cet article présente une approche possible pour concevoir un moteur de jeux, appelée “Entity-Component-System” ou ECS. Il n'est pas possible de présenter toutes les problématiques que l'on peut rencontrer avec l'ECS, ni aborder toutes les implémentations possibles de l'ECS pour tous les types de jeux possibles. Le but est avant tout de vous donner les bases de compréhension de cette architecture et des pistes de réflexions pour l'adapter selon vos besoins.
Ce tutoriel se décompose en quatre parties :
- les approches classiques utilisées dans la conception des jeux ;
- la théorie de l'ECS et les problématiques de son implémentation ;
- les besoins détaillés de jeux (moteur graphique, intelligence artificielle, gestion des entées, etc) dans le cadre d'un ECS ;
- une réflexion plus large sur la possibilité d'utiliser l'approche ECS en dehors des jeux vidéos.
Critères de qualités et approches historiques
Avant de commencer à étudier le fonctionnement des ECS, il est important de rappeler les critères de qualités logicielles qui permettent d'orienter les choix de design des moteurs de jeux et de survoler les problèmes présentés par les approches classiques des moteurs de jeux.
Qualités d'un moteur de jeux
Un moteur de jeux est un programme comme un autre, il doit donc suivre dans l'idéal les critères habituels de qualité logiciel. Cependant, il y a deux points qui ont une importance particulière pour les jeux.
Performances
Ce point dépend fortement du type de jeux que l'on souhaite créer et les plateformes sur lesquelles le jeu sera utilisé. Une attention particulière doit être portée si on souhaite créer un jeu complexe dans un univers 3D riche. La réalisation de rendus 3D réalistes consomme énormément de ressources de la carte graphique, tandis que des fonctionnalités comme l'intelligence artificielle ou des simulations physiques réalistes (mouvements des cheveux et des vêtements, environnements destructibles) consommeront davantage le processeur central. Même un simple jeu 2D peut se révéler être un challenge en termes d'optimisation des performances si l'on souhaite le faire tourner sur un téléphone mobile ou une box connectée à une télévision.
Maintenabilité et évolutivité
La maintenabilité désigne la facilité à corriger les problèmes existants et l'évolutivité à ajouter de nouvelles fonctionnalités. L'une des plus grosses erreurs que l'on rencontre dans les projets de jeux amateurs est probablement l'envie de créer un jeu complet et riche dès le départ. Les amateurs ont généralement une vision de ce qu'ils veulent obtenir (plus ou moins), mais pas de la démarche correcte pour y parvenir.
Dans le développement logiciel classique, la question ne se pose généralement pas. Il est nécessaire de livrer des versions intermédiaires du logiciel, fonctionnelles mais ne contenant pas la totalité des fonctionnalités. Chaque nouvelle livraison corrigera les bugs de la version précédente et ajoutera de nouvelles fonctionnalités. Cette différence de démarche peut être résumée par la figure suivante :

Dans les jeux vidéos, l'évolutivité prend un sens particulier. Les jeux sont (dans le meilleur des cas) développés par des équipes hétérogènes, composées en particulier de développeurs (vous) et de game designers (souvent appelé “les autres” ou encore “the bad guys” ;) ). Les game designers ont besoin de pouvoir modifier le comportement des éléments du jeu le plus facilement possible, en général en passant par un langage de script comme lua. Il faut dans ce cas éviter les conceptions qui nécessiterait de devoir recompiler pour modifier les comportements.
Conséquences sur les moteurs de jeux
Ces critères de qualité logiciel ne sont pas rappelés sans raison. Lorsque l'on doit faire des choix sur la conception a adopter pour concevoir un moteur de jeux, il est nécessaire de conserver ces critères en tête. Dans un monde idéal, on pourrait choisir de respecter tous les critères de qualité et de les appliquer à 100%. Dans le monde réel, ce n'est pas possible.
En particulier, le critère de performances s'oppose souvent au critère de maintenabilité. Une autre erreur classique est de recherche en premier lieu la performance maximale, quitte à sacrifier la lisibilité du code et augmenter les risques d'erreur. Ainsi, en C++, on rencontre souvent du code old-school (mélange de C++ et de C bas niveau), ce qui pose régulièrement des problèmes d'exécution (c'est probablement le pire type d'erreurs, puisque ces erreurs ne produisent pas de messages d'erreurs claires, produisent un comportement indéterminé non reproductible, il est parfois très difficile de trouver la source de l'erreur).
Ceux qui suivent cette approche font deux erreurs :
- ils ne savent pas faire de compromis sur les performances. Même si un code old-school peut parfois être un plus rapide que son équivalent en C++ moderne sur le papier (c'est souvent l'argument utilisé pour rejeter les tableaux du C++ comme
std::vectorou d'utiliser les pointeurs intelligents versus les pointeurs nus), cela ne veut pas dire que ces pseudo-optimisations auront un impact perceptible par le joueur. - ces codes produisent plus facilement des erreurs difficiles à débugger. Les développeurs sont obligés de passer beaucoup de temps pour trouver ces erreurs et les corriger. Ce temps est perdu pour développer de nouvelles fonctionnalités ou d'optimiser des parties du code qui ont un réel problème de performances.
On voit ici que les critères de maintenabilité et d'évolutivité du code sont prioritaires dans les choix de conception d'un moteur de jeux (et d'un logiciel en général). Lors de l'étude des ECS, nous essayerons d'analyser l'impact des différentes implémentations possibles selon ces critères.
Structures d'un moteur de jeux
Un moteur de jeux est quelque chose de complexe. La raison est simple : un jeu en lui même est quelque chose de complexe. Si on prend en compte que les éléments visuels d'un jeu, on doit gérer l'environnement (sol, arbres, rivières, élément de décors avec les quels le joueur peut interagir ou non), les personnages et monstres (déplacements dans l'univers du jeu, animations du corps, comportement), l'interface utilisateur (barres de vie, noms, dégâts subis et point de vie générées), l'enrichissement graphique (effets visuels pour les sorts lancés, flous, particules), la simulation physique (collisions et chutes, animation des cheveux et des vêtements, moteur de particules pour simuler le feu et la fumée).
A cela, il faut aussi ajouter tout ce qui n'est pas visible directement, mais a un impact important sur le plaisir du joueur : le réseau (mise à jour du jeu, jeux à plusieurs), les fichiers (enregistrer les parties en cours, avoir un chargement fluide des données pour éviter les ralentissements), gérer les entrées (clavier, souris, manette de jeux, écran tactile, kinect), les sons (musiques d'ambiance, bruitages, détection des ennemis par le bruit), intelligence artificielle (comportement des personnes non joueur et des ennemis), le scénario (raconter une histoire, suivre un script).
Pour s'en convaincre, il suffit de voir la structure d'un tel moteur, extrait du livre “Game Engine Architecture” :

(Extrait du livre “Game Engine Architecture”)
Fondamentalement, un moteur de jeux est donc un ensemble d'éléments de jeux (entités), qui interagissent ensemble. Une boucle parcourt tous ces éléments pour les mettre à jour régulièrement en fonction des actions du ou des joueurs.
Les approches historiques
Les approches possibles pour créer un jeu sont nombreuses, en particulier à l'époque où l'on n'avait pas encore pensé à créer des moteurs de jeux réutilisables et où chaque jeu repartait de zéro. Le but de cette partie n'est pas d'être exhaustive, nous allons présenter que les approches objets les plus classiques.
Remarque : ces approches ne sont pas forcément nommées de manière aussi formelle que ce que nous présentons ici. Ces noms ont été choisis pour faciliter la description.
Hiérarchie profonde d'héritages (Deep Inheritance Hierarchy Approach)
Pour ceux qui ont suivi le cours de C++ du site OpenClassroom (ou du Site du Zéro), cette approche est bien connue, puisque ce cours l'utilise comme exemple pour apprendre la programmation objet. L'idée est que lorsque deux classes ont des propriétés communes, il est possible de créer une classe parente qui contiendra ces propriétés communes. Les deux classes dérivent de cette classe parente et implémentent uniquement les propriétés qui sont spécifiques à chaque classe.
Par exemple, un joueur et un ennemi sont deux personnages, ils se différencient par le fait que le premier est contrôlé par le joueur, le second par une intelligence artificielle. Il est donc possible d'écrire une classe parente Personnage, qui implémente par exemple le rendu 3D d'un personnage, l'animation des mouvements, les collisions avec les décors. A côté de cela, la classe Player implémente la gestion des entrées (clavier, souris, manette de jeux) et la classe Enemy implémente l'intelligence artificielle.
On procède de la même manière pour tous les objets. Ainsi, la classe Personnage pourra dériver de la classe Mobile, qui implémenter ce qui peut bouger, qui dérive elle-même de Drawable, qui implémente tout ce qui peut être dessiné à l'écran, qui dérive de Objet, qui représente n'importe quel élément du jeu.
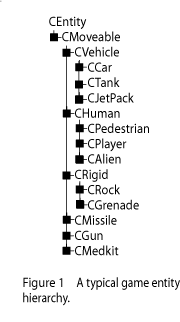
(Source : http://cowboyprogramming.com/2007/01/05/evolve-your-heirachy/)
En termes d'implémentation, cette approche est relativement simple à concevoir. Il suffit de regrouper les méthodes et attributs communs dans une classe et de dériver de cette classe. Tous les objets sont parcourus par une boucle, qui appelle une fonction commune de mise à jour (classiquement, on appelle cette fonction update).
class Object { public: virtual void init(); // initialise les objets virtual void update(); // met à jour les objets }; class NonDrawable : public Objet { }; class Drawable : public Objet { public: void init() override; void update() override; void init3D(); // initialise le contexte 3D void draw3D(); // dessine l'élément 3D private: 3dData data_; // données graphiques 3D (triangles, textures, etc) }; class Mobile : public Drawable { public: void init() override; void update() override; void initAnimation(); // initialise la première position de l'animation void nextAnimation(); // passe à la position suivante de l'animation private: Animations animations_; // données permettant d'animer les objets }; class Player : public Mobile { public: void init() override; void update() override; private: Input input_; // données permettant de gérer les entrées }; class NonPlayer : public Mobile { public: void init() override; void update() override; private: IA ia_; // intelligence artificielle }; int main() { // création de tous les éléments du jeux std::vector<std::shared_ptr<Object>> objects; // initialisation des objets for (auto & object: objects) { object->init(); } // mise à jour des éléments du jeu while (bool continue{true}) { for (auto & object: objects) { object->update(); } } }
Cette approche peut sembler intéressante en termes de non répétition du code (si un code est commun à deux classes, il suffit de le déplacer dans la classe parente) et d'évolutivité (si on veut ajouter une nouvelle classe, il suffit de la faire hériter d'une classe existante).
En pratique, ce n'est pas le cas. Pour pouvoir déplacer un code commun entre deux classes dans une classe parente, encore faut-il qu'il existe une classe parente. Il y a toujours la possibilité de remonter jusque la classe Object, mais on se retrouve au final à avoir une super-classe (on parle de god-object) qui remplit tous les rôles. Ce type de classe entre en violation directement des principe de responsabilité unique (SRP - Single Responsabilty Principle) et ouvert-fermé (OCP - Open-Close Principle) :
- le principe de responsabilité unique stipule qu'une classe ne doit faire qu'une seule chose (mais bien) ;
- le principe ouvert-fermé stipule que les classes doivent être fermée à la modification, mais ouverte à l'évolution (dit autrement, cela signifie que pour ajouter une nouvelle fonctionnalité, il ne faut pas modifier une classe existante, mais ajouter une nouvelle classe).
(Voir les références en annexes pour des sources sur les principes SOLID.)
Design pattern Visitor
Le design pattern Visitor permet de parcourir une collection hétérogène, c'est-à-dire une collection composé d'objets de types différents, et d'appliquer un traitement sur les objets d'un certain type. Il peut donc être intéressant de l'utiliser ici.
Prenons par exemple la hiérarchie de classe décrite précédemment. La collection objects est un vector contenant des objets de type NonDrawable et Drawable. On souhaite affiche les éléments graphiques, pour cela, on écrit une boucle qui parcourt tous les éléments et appelle la fonction draw3d. Le problème est que les objets NonDrawable ne possèdent pas cette fonction, on ne peut appeler que les fonctions déclarées dans l'interface de la classe Object.
Cependant, les objets sont polymorphiques, on va pouvoir les convertir (cast) si cela est possible. On va donc pouvoir écrire quelque chose comme cela :
for (object & : objects) { auto drawable = dynamic_cast<shared_ptr<Drawable>>(object); if (drawable) { drawable->draw3d(); } }
Autrement dit, on essaie de convertir l'objet en Drawable et si cette conversion réussit, alors on appelle la fonction draw3d.
Ce code est problématique, parce qu'il implique de devoir connaître le type de l'objet que l'on manipule pour pouvoir appliquer un traitement (ce qui est contraire au principes de programmation objet et implique que le RTTI - Run-Time Type Information - soit activé, ce qui diminue les performances).
Le design pattern Visitor apporte une solution à ce problème, basé uniquement sur l'appel de fonctions virtuelles. Pour cela, il faut commencer par ajouter une fonction accept dans Object pour accepter les visiteurs et qui ne fait rien (mais elle ne doit pas être virtuelle pure).
class Object { public: virtual void accept(std::weak_ptr<Visitor> visitor) {} };
Les visiteurs implémentent le traitement à appliquer selon le type réel des objets. Pour appliquer ce traitement, il faut surcharger cette fonction accept dans les classes qui doivent accepter les visiteurs. Les visiteurs possède une fonction particulière pour chaque classe qui accepte les visiteurs, il faut donc appeler cette fonction dans la fonction accept. Par exemple, pour que les classes Drawable et NonPlayer acceptent les visiteurs :
class Drawable : public Objet { public: void accept(std::weak_ptr<Visitor> visitor) override { assert(visitor); visitor.lock()->visitDrawable(this); } }; class NonPlayer : public Mobile { public: void accept(std::weak_ptr<Visitor> visitor) override { assert(visitor); visitor.lock()->visitMobile(this); } };
Pour terminer, il faut écrire les visiteurs, en commençant par la classe parente Visitor, qui propose toutes les fonctions virtuelles visitXxx possibles. Ensuite, on peut implémenter les fonctions visitXxx spécifiques pour une classe visitée dans un visiteur dédié à chacune d'elle.
class Visitor { public: virtual void visitDrawable(std::weak_ptr<Drawable> drawable) {} virtual void visitMobile(std::weak_ptr<Mobile> mobile) {} }; class VisitorForDrawable : public Visitor { void visitDrawable(std::weak_ptr<Drawable> drawable) override { // applique un traitement sur les objets Drawable ici } }; class VisitorForMobile : public Visitor { void visitMobile(std::weak_ptr<Mobile> mobile) override { // applique un traitement sur les objets Mobile ici } };
Dans la boucle principale, si l'on souhaite appliquer un traitement sur un certain type d'objets, il suffit donc de créer le visiteur correspondant à ce type d'objet et d'appeler la fonction accept sur l'ensemble des objets. Pour les objets de type correspondant, la fonction virtuelle accept de la classe dérivée sera appelée, ce qui appellera la fonction visitXxx du visiteur. Pour les autres classes, ça sera la fonction accept de la classe parente Object qui sera appelée, qui se fait rien.
int main() { auto visitor = make_shared<VisitorForDrawable>(); for (auto & object: objects) { object->accept(visitor); } }
L'intérêt du design pattern Visitor est que si l'on veut ajouter un comportement particulier, on ne doit modifier que la classe qui accepte ce comportement, en ajoutant une fonction accept, et créer une nouvelle classe VisitorForXxx correspondant à ce comportement.
Le problème de ce design pattern est qu'il faut que la classe Visitor connaissent toutes les fonctions VisitXxx possibles, ce qui complexifie le code.
Héritage multiple de comportements
La problématique des hiérarchies d'héritage est qu'il est parfois difficile de trouver une classe parent dans laquelle implémenter une fonctionnalité et c'est la classe Object qui récupère au final toutes ces fonctionnalités. Une solution consiste à séparer ces fonctionnalités dans des classes indépendantes, que l'on appelle composant. Chaque composant est chargé d'implémenter un type de comportement.
Par exemple, on peut implémenter de comportement Drawable, Movable, Attack, etc. On peut également implémenter plus finement les comportements, comme par exemple si a un ennemi qui attaque en fonçant sur sa cible et un autre qui attaque en contournant sa cible, on pourra écrire des comportement DirectAttack et ForwardAttack.
La première approche pour créer des entités composées de ces éléments est de faire hériter les classes de ces composants, en utilisant l'héritage multiple. La seconde est de créer une entité par composition des composants. Nous allons voir la première approche dans cette partie et la seconde dans la prochaine partie.
L'héritage multiple est une fonctionnalité du C++ qui permet de faire hériter une classe de plusieurs autres classes. L'interface de la classe finale contient donc toutes les interfaces de ses classes parentes.
class A { public: void foo(); }; class B { public: void bar(); }; class C : public A, public B { }; int main() { C c; c.foo(); // ok, C contient A c.bar(); // ok, C contient B }
Pour créer les composants, on créé une classe spécifique pour chaque comportement que l'on souhaite implémenter. Par exemple, si on veut créer des éléments affichables, on peut créer une classe Drawable contenant les fonctions init3d et paint3d déjà décrite dans la première partie. On peut également créer une hiérarchie de comportements, mais en évitant les hiérarchies profondes. Par exemple, pour l'intelligence artificielle, on peut créer un comportement Attack, puis deux autres classes qui dérive de celle-ci, DirectAttack et ForwardAttack. Pour un objet dont la classe hérite d'une comportement donné, on peut appeler directement les fonctions correspondantes à ce comportement.
Il ne sera pas possible d'utiliser le design pattern Visitor avec cette approche, puisqu'il n'est pas possible d'écrire une fonction accept dans chaque comportement. Il faudra donc utiliser dynamique_cast pour vérifier les classes qui possèdent ou non un comportement donné.
class Object {}; class Drawable { public: void init3d(); void paint3d(); } class Attack { public: int health() const; // connaître le nombre de point de vie restant void attack(int damage); // applique des dégâts }; int main() { std::vector<std::shared_ptr<Object>> objects; for (auto & object: objects) { auto drawable = dynamic_cast<std::shared_ptr<Drawable>>(object); if (drawable) { drawable->paint3d(); } } }
Le principal problème avec cette approche est que la liste des comportements appliquées à une entité est déterminée à la compilation. Il n'est pas possible par exemple qu'une entité acquière la compétence Vol si on n'a pas ajouté ce comportement dans la liste des classes parentes. Il n'est alors pas possible aux game designers de modifier les comportements sans passer par la modification du code existant et la recompilation du programme.
Liste de comportements par composition
A lieu d'utiliser l'héritage, qui impose une structure définie à la compilation, il est également possible de créer une liste de composants par composition. Pour cela, on va utiliser une classe parente pour tous les composants et utiliser dynamic_cast pour tenter de convertir le composant en son type réel (ou utiliser une fonction type() qui retourne le type réel du composant).
class Component { public: enum class Type : int { Unknow, Graphics, Animation, /* autant que l'on veut */, UserDefined }; virtual int type() const { return Type::Unknow; } }; class GraphicsComponent : public Component { public: int type() const override { return Type::Graphics; } void draw(); }; class Entity { public: auto begin { return components.begin(); } auto end { return components.end(); } private: std::vector<std::shared_ptr<Component>> components; }; class World { public: void update() { for (auto const& entity: entities) { for (auto const& component: entity) { if (component->type() == Component::Type::Graphics) { auto c = static_cast<shared_ptr<GraphicsComponent>>(component); c->draw(); } } } } private: std::vector<std::shared_ptr<Entity>> entities; };
Cette approche présente également le problème de devoir connaître le type réel des classes pour pouvoir les utiliser. Encore une fois, le design pattern Visitor pourra faciliter les choses.
Il est également possible de séparer les composants en catégories, ce qui peut simplifier l'héritage entre les classes. Par exemple, au lieu de faire dériver tous les composants de Component et de tout mettre dans un vector unique, on va créer un attribut pour chaque type de composant que l'entité peut contenir.
class GraphicsComponent { public: void draw(); }; class Entity { std::unique_ptr<GraphicsComponent> graphics; std::unique_ptr<IAComponent> ia; std::unique_ptr<CollisionComponent> collision; };
Il suffit alors de tester si un composant est valide ou non pour savoir si l'entité contient ce composant. On peut également appeler directement ces composants.
class World { public: void update() { for (auto const& entity: entities) { if (entity->graphics()) { entity->graphics()->draw(); } } } private: std::shared_ptr<Component> component; };
Design pattern Strategy
Un dernier mot rapide sur le design pattern Strategy. Ce design pattern sert à modifier dynamiquement le comportement d'une classe, en utilisant une seconde classe qui contient l'implémentation réelle. L'équivalent compile-time de ce design pattern est la classe de Politique.
class ImplementationInterface { public: virtual void do_function() = 0; }; class Implementation : public ImplementationInterface { public: void do_function() override { /* do something */ }; }; class ModifiableComportement { public: void function() { impl->do_function(); } private: std::unique_ptr<ImplementationInterface> impl;
Notez aussi que l'on utilise aussi le design pattern NVI - Non Virtual Interface dans ce code.
Dans les codes d'exemples précédents, certains composants sont en fait des applications de ce design pattern. Le comportement réelle des entités est déterminée par ses composants, il suffit de créer un nouveau type de composant pour modifier le comportement ce l'entité. Cela permet d'avoir un code facilement évolutif et permet aux game designers de “construire” une entité à partir de ces briques élémentaires, sans avoir besoin de connaître comment sont implémentés ces composants.
On voit qu'il existe de nombreuses implémentations possibles pour concevoir un moteur de jeux. Selon les contraintes, ces approches peuvent être suffisantes. Dans le cas contraire, l'ECS est une solution supplémentaire, qui présente d'autres avantages.
Théorie et implémentations d'un ECS
Les approches décrites dans le chapitre précédent ont une chose en commun : elles sont basées sur la programmation orientée objet. L'ECS est au contraire basé sur la programmation orienté données Data-driven programming.
Nous allons voir dans un premier temps a quoi correspond cette approche et ce qui la distingue de la programmation objet. Nous verrons ensuite comment implémenter concrètement un ECS en C++.
Data-driven programming
Importance du DDP? Exemple pour illustrer avec comparaison avec la complexité algo
Vous avez peut etre vu la notation O(n) pour la complexité algo.
1. O(n) avec constante, depend de matos. Certains algo vont utiliser des fonctionnalités du CPU et donc etre plus performant, meme en ayant une O(n) plus mauvaise. En particulier vectorisation, mem cache, GPU, etc. qui fait que certains algos ont un moins bon O(n) mais sont plus performant en pratique (meilleur utilisation des caches, meilleur utilisation des threads, etc)
2. O(n) mesure un comportement asymptomatique, donc n→infini. Mais en pratique, ce n'est jamais infini, et dans dans un domaine particulier de n, un algo peut etre plus performant. Par exemple, algo plus performant sur petite taille de n. Un exemple concret, certains algo de tri utilisent un methode pour faire un premier tri en bloc de taille N, puis utilisent un autre algo pour trier chaque block (de petite taille).
3. O(n) est une mesure de la complexité. Autre : big-theta, big-omega, etc. https://en.wikipedia.org/wiki/Big_O_notation. Pour rappel, avec une liste spécifique de valeurs de taille n, il y aura un temps mesuré t. Chaque liste de valeurs va donner des temps différents. Pour chaque algo, il y a une donc un t_min et un t_max pour chaque valeur de n et l'ensemble des mesures de perfs d'un algo est un enveloppe. Les notations O, theto, omega, etc. mesure un parametre particulier de cette envoloppe : par exemple le plus mauvais cas, le cas moyen, etc.
Du coup, pour des données reels dans un cas d'utilisation particulier, il est possible de ne pas être dans l'enveloppe complete, mais dans un sous groupe, et dans ce cas, la mesure de complexité peut etre mauvais. Par exemple, certains algos de tris sont plus efficace quand la majorité des valeurs sont deja trié et qu'il y a peu de valeur a déplacer (ce qui arrive par exemple quand vous ajoutez de nouvelles données dans un tableau deja trié).
Pour resumer, il y a donc des caractéristiques sur les donne2es dans un contexte et cas d'utilisation particulier, qui peu influencer le choix de l'algo, le choix des structures de données, etc. Le principe de data driven dev est d'optimiser le choix des algos par rapport aux donne2es.
Note : c'est important ausi dans les tests. On test souvent en utilisant des valeurs particuliere ou des valeurs aleatoire, mais cela peut etre important aussi de faire des tests avec des données reelles.
Différentes approches pour concevoir les choses
Notes sur le programmation orientée objet
La programmation orienté objet se décrit en termes de services rendus par les classes et d'interactions entre les objets. Elle se base pour celas sur l'encapsulation de comportements (et donc incidemment sur l'encapsulation de données, mais cela n'est qu'une conséquence de l'encapsulation, pas le besoin primaire de l'encapsulation).
Prenons un exemple concret : une épée dans un jeu. Cette arme rend le service suivant : “faire mal” (que l'on traduit généralement en “faire des dégâts” ou “diminuer les points de vie de la cible”… mais c'est plus amusant de dire “faire mal” :)). Et elle va interagir avec plusieurs autres éléments du jeu : au moins le propriétaire de l'arme et celui qui reçoit les dégâts (parfois, c'est la même personne…).
Le code correspondant est donc le suivant :
class Sword { public: void attack(Target & target); };
Remarque : on voit parfois le type de code suivant :
class Sword { public: int getDegats() const; }; class Target { public: int getPV() const; void setPV(int pv); private: int pv; }; int main() { Target target; Sword sword; target.setPV(target.getPV() - sword.getDegat()); }
Dit autrement, cela veut dire que la cible possède des points de vie, l'arme possède des points de dégâts et pour calculer le résultat d'une attaque, on calcule la différence entre les deux. Même si l'idée est correcte (c'est comme cela que l'on procède lorsque l'on joue à un jeu de rôle sur plateau), ce type de code ne respecte pas l'encapsulation des comportements et encore moins la loi de Demeter.
Ce type de code ne présente pas les critères de qualité logiciel demandé par la programmation objet. Dit autrement, cela ne sert à rien de faire une classe qui ne sert qu'à présenter les données qu'elle contient.
Data-driven programming
Dans l'approche orientée données, on va concevoir les choses comme un flux de données, qui vont subir un certains nombres de modifications.
ECS
ECS peut être représenté comme un tableau avec les entités et systèmes en ligne et colonne, les composants sont a l'intersection des 2.

Définition générale :
- entité = un id uniquement
- composant = data
- système = algos
Les éléments constitutifs des ECS
Les entités
Nombreuses sources simplifient l'entité à un simple identifiant. Exemple :
using entity = int; // C++03 // typedef int entity
Sous forme d'une classe. Création via factory, pour garantir l'unicité de l'id
class entity { int id {}; }; class entity_factory { int create(); };
Code plus évolué, avec classe ID (permet de cacher le type réel de ID, qui peut être un nombre, plusieurs nombres, un string, etc. Juste un besoin = tester l'égalité ?)
class ID { public: bool operator==(ID const& id) const; static ID generate(); };
Plusieurs méthodes pour créer un id unique. 1. avoir un static, l'incrémenter à chaque utilisation. Problème : si id est supprimé, non réutilisé. 2. Parcourir la liste des id affectés et choisir le premier libre. Problème : prend du temps.
Remarque : prendre un id int32 et incrémenter, peut sembler ok. Mais MMO avec plusieurs millions de joueurs et qui ne redémarre jamais (donc non réinitialisation des id)
Autre approche : entité est une liste de composants
Entity monster = new Entity(); monster.attach(new StatsPart(100, 2)); // If we don't want our monster to fly, simply uncomment this line. monster.attach(new FlyingPart(20)); // If we don't want our monster to cast spells, simply uncomment this line. monster.attach(new SpellsPart(5)); monster.attach(new MonsterControllerPart(target)); monster.initialize(); return monster;
Qui est propriétaire des composants ?
vector<component>dans entityvector<component>dans system etvector<reference_wrapper<component»dans entity- objet polymorphique :
vector<shared_ptr<component»dans entity etvector<weak_ptr<component»dans system (ou l'inverse) - pas de super-composant parent :
vector<any<component» - un super-parent par system :
vector<component_system>, comment les liés dans entité ? (avecany<component>?)
Les composants
Utilisation une pool de composant. Nécessite objet parent Component
Ou boost::properties ? (liste de string + valeurs)
class component : non_copyable { entity e; system s; // nécessaire ? }; class component_pool { vector<component> components; void push_back(component); // accès aux composants vector<reference_wrapper<component>> extract_by_entity(entity const&); vector<reference_wrapper<component>> extract_by_system(system const&); }; class component_factory { map<string, component> components; map<string, pair<component, system>> components; // lier un composant à un système ? map<int, component> components; // utilisation de int au lieu de string ? // avec utilisant d'un "dico" pour faire le lien "nom" et "id" void register(string const& name, component c, /* system const& s ? */); component create(string const& name); }; class composant_identifier { map<string, int> names; // ou vector<string> ? void register(string const& name, int id); int register(string const& name); // id donné par la classe int id(string const& name); };
Les systèmes
Besoin de supprimer un système ?
namespace component { class component { int entity_id {}; virtual void update() = 0; }; class render {}; class ia {}; class physique {}; } namespace system { class system { vector<unique_ptr<component>> components; void update() { foreach(begin(components), end(components), update); } }; class render { virtual void update() override; }; class physique { virtual void update() override; }; class ia { virtual void update() override; }; } class entity { int id {}; }; vector<unique_ptr<system>> systems; foreach(begin(systems), end(systems), update);
Les interactions
On peut distinguer les interactions suivantes :
- entre éléments de même types (entité-entité, composant-composant et système-système) et entre éléments de types différents
- “horizontale”, “verticale” ou “diagonale” (je me réfère au schéma suivant)
Interactions "verticales"
- entité ↔ entité : je ne vois pas a priori le besoin auquel répondrait des interactions entités-entités, donc non.
- système ↔ composant et composant ↔ composant (d'un même système et différentes entités) : c'est le boulot des systèmes, cela fait partie du design des ECS.
Interactions "horizontales"
C'est le plus compliqué. Pour faire leur boulots, certains systèmes doivent accéder aux informations de plusieurs composants. Il est possible d'implémenter cela en mettant dans les différentes éléments un “lien” vers un autre élément (par exemple une référence dans un composant vers un autre composant, conserver un identifiant de l'entité, etc)
- système ↔ système : ils sont assez simple à mettre en place, puisque ces objets sont créés ensemble. Par contre, cela ajoute un couplage entre les classes, donc a éviter.
- entité ↔ composant et composant ↔ composant (d'une même entité et différents systèmes).
Conceptuellement, les composants sont liés à une entité. Comme doit on implémenter ce “lien”. Et pourquoi faire ?
Le premier besoin est que si on supprime une entité, il faut aussi supprimer ses composants. On peut régler cela en conservant un tableau de composants dans les entités (mais cela impose que toutes les entités dérivent d'un même god object “composant” et que l'entité ne soit pas un simple id) ou avoir un id dans chaque composant (on aura aussi probablement un god-component).
Le second besoin est que pour que les systèmes fassent leur boulot, ils doivent accéder aux informations de plusieurs composants. Dit autrement, pour les interactions “horizontales”, cela veut dire qu'a partir d'un composant donnée, il faut pouvoir aller chercher les autres composants d'une entité. Il est possible de :
- conserver un id entité dans le composant puis parcourir les composants pour trouver ceux qui ont le même id.
- de conserver une référence/pointeur vers le composant qui nous intéresse (de la même entité. A voir comment gérer les créations/destructions dynamiques de composants - voir ensuite)
- conserver l'id entité puis aller dans les entités et utiliser la liste des composants liés à une entité (mais cela pose problèmes comme expliqué avant)
Pour le pointeur/référence, une remarque. Si on créé un composant “ia” qui a une référence vers un composant “position”, le builder du composant “ia” sait qu'il a besoin du composant “position”, cela ne pose pas de problème qu'il “demande” au système “position” de lui fournit cette référence sur le composant “position” qui l'intéresse. Pour la mise à jour du lien, c'est plus compliqué. Si on détruit le composant “position”, il n'y a a priori aucune raison que le deleter du composant “position” sache qu'il est référencé par une autre composant. Pourtant, il faut quand même que le composant “ia” sache qu'il n'a plus accès au composant “position”.
Comment résoudre cela ? Peut être un élément “cleaner”, qui détruit les composants inutiles lorsque l'on détruit un composant (on peut imaginer qu'un composant qui utilise un autre composant ne peut plus fonctionner si le premier est supprimé. Par exemple, un composant “ia” qui attaque un personne devrait être détruit et remplacer par un composant “ia” “je glande sur place” si le personnage utilise une magie pour disparaître). Ou un DP observer ?
Interactions "diagonales"
A priori, non pour toutes (entre entité ↔ système ou entre composant ↔ composant de systèmes et entités différentes). Le seul cas que je verrais d'interactions diagonale, c'est si un composant doit accéder directement aux informations d'une autre entités. Par exemple, les composants “IA” qui utilisent l'algo A* et qui ont tous besoin de connaître la position de l'entité “player”.
Mais cela ajoute un couplage entre les composants qui n'est pas simple à résoudre. Il est possible de régler cela en créant une référence vers l'entité “player” ou le composant “position” de l'entité “player” (que faire s'il y a plusieurs “players” ?) et utiliser un builder pour créer les composants en attachant l'entité “player” à ces composants directement lors de la création des objets.
Mais on peut vouloir conserver plus de souplesse dans le code. Par exemple, on peut imaginer que les entités “monstre” n'attaquent pas directement les entités “player”, mais qu'il y a un système de détection (cône de vision des monstres, détection au son, etc) qui détermine pour chaque entité (aussi bien pour les “monstres” qui détecte le “player” que le “player” qui détecte un ennemi) qui détecte qui. Ensuite, le système “IA” interagit avec les composants “détection” et “position” pour déterminer les déplacements.
Donc le lien directe à un autre composant ou une entité particulière dans les composants est à éviter.
Problématiques générales
Créer et détruire les entités
Quand et comment ?
entity player { 1 }; vector<string> const components { "render", "movable" }; class component_factory { map<string, pair<unique_ptr<component>, reference_wraper<system>> components; public: void register(name, component, system) { components.insert(name, make_pair(component, system)); } void create(entity, name) { component c = components[name]; c.entity_id = entity.id; system.register(c); } } class entity_builder { int last_id {}; component_factory f {}; public: entity create(vector<string> c) { entity e { ++last_id }; foreach(begin(c), end(c), [](auto name) { f.create(entity, name); } return e; } }
Intérêt factory : pouvoir ajouter dynamiquement des composants = plugins
Liste de composants constituant une entité = scriptable. On peut écrire :
Entity { name: player Component { type: "ia" paramètre_1: 123 paramètre_2: 3.1415 } Component { type: "render" mesh: "player.3ds" } }
Créer et detuire les composants
Quand et comment ?
Suppression entité : supprimer les composants correspondant
Comment définir la liste des systèmes ?
- inputs
Comment faire un system d'input dans un ECS ? Plusieurs ? (Chaque joueur controle son perso, ou un joueur peut changer de personnage controlé)
- ia
- render
- physique
- sons
- etc.
Comment définir la liste des composants ?
Qu'est ce que l'on peut/doit mettre dans les composants ? Comment choisir ?
Dépend de la granularité que l'on veut. Par exemple, une arme avec des modificateurs (magie, flèches spéciales, etc). Premier cas, composant “normal”, avec modificateur créé à la création de la classe (non modifiable)
class component { string name {}; int damage {}; }; component c("arc", 10); component c("arc de feu", 15);
2 : liste fixe de modificateurs. Peut ajouter ou supprimer des propriétés pendant le cours du jeu, mais liste des propriétés est fixe
class component { string name {}; int damage {}, int magic {}; int arrow {} }; component c("arc", 10); component c("arc de feu", 10, 5);
3 : liste dynamique de modificateurs. Liste des propriétés peut être modifiable, mais pas les méthodes de calculs (par exemple ici, dégat = damage + somme modificateurs)
class component { string name {}; int damage {}; vector<pair<string, int> modifiateurs }; component c("arc", 10); component c("arc", 10, { "de feu", 5});
4 : liste de components. Arme = entité, Dégât = system, Modificateur de dégâts = component. Possibilité de modifier les méthodes de calculs des modificateurs (par exemple, un sort qui n'ajoute pas de dégâts, mais qui double les dégats de feu)
class FireDamage { int modifier {}; int damage_modifier(int damage) { return damage + modifier; } }; component_factory.register("magie feu", FireDamage(5)); entity e = entity_builder.create("arc", { "magie feu" });
Des composants plus perfectionnés
Possibilité de créer des composants en utilisant des hértiage, composition, template, sous-composants plus simple, etc.
- Peut-on mélanger ECS et héritage ? (PickableComponent base de ScorePickableComponent ? Si oui, alors comment alors traiter ce que doit faire chaque type de PickableCOmponent, genre augmenter score ou faire un power up, si non, comment faire pour résoudre le cas précédent ?)
- Comment supprimer une entity ? Simple id = parcourir la liste de tous les composants pour supprimer ce qui doivent l'être. Liste de composants dans entity ?
Interactions entre entités, entre systèmes, entre composants
- entre composants de même système ?
- entre composants de même entité ?
- quelconque ?
Parfois, besoin interaction. Comment les faire interagir ?
Par exemple render à besoin de savoir la position de l'entité (pour la positionner dans la scène), l'état (afficher le sprite correspondant à un personnage qui marche, qui attend, qui cours, etc)
Par exemple : Un Collisions system doit gerer comment une collisions avec un ExplosiveComponent ?)
exemple : player meurt (composant “vie” == 0), comment changer le composant “etat” ? D'autres composants à changer ?
Mettre les données dans les composants et accès aux composants par plusieurs systèmes. Comment ?
Autre : event ? signaux-slots ?
Création d'ECS via fichier
comment lire un fichier et créer les ECS ? Exemple d'implémentation simple avec fichier texte
Aller plus loin : xml, lua, etc.
Game loop
Besoins :
- mettre à jour les ECS
- éviter de parcourir des composants si pas nécessaire (performance ?)
- base de temps différente selon les systèmes (par exemple physique mis à jour à 120 fps, graphiques à 60 fps ?)
- enties.update_all() ? ou systems.update_all() ?
Entity villager = createVillager(); Entity monster = createMonster(villager); // very basic game loop while (true) { villager.update(1); monster.update(1); Thread.sleep(1000); }
À trier
- Éviter de parcourir tous les composants. Comment parcourir une sous-liste de composants ? D'entité ;
- Exemple : collision. Quadtree, octree, bounding box, etc. (spatial partitioning) ;
- sauvegarder l'état du jeu ? (liste des entités, des composants) Passer les informations via réseau ? (sérialisation) ;
- hiérarchie d'entités : relation entre plusieurs entités liées
Exemple: 3 persos A (marchent à côté du char), B (dans le char), C (dans la tourelle), 1 char avec tourelle.
| Entité | Composant position relative | Composant “Transporte quelque chose” |
|---|---|---|
| A | x_a, y_a | |
| B | x_b, y_b | char |
| C | x_c, y_c | tour |
| char | x_char, y_char | |
| tourelle | x_tour, y_tour | char |
Au final, la position absolue (X, Y) des objets dans le monde est calculée en fonction des positions relatives et des dépendances :
- X_char = x_char
- X_tour = x_tour + x_char
- X_A = x_a
- X_B = x_b + x_char
- X_C = x_c + X_tour = x_c + x_tour + x_char
Proposition d'implémentation
- main.cpp
#include <cassert> #include <iostream> #include <vector> #include <algorithm> /******* Entity *******/ using Entity = size_t; /******* Entities *******/ class Entities { public: Entities(size_t size = 1000); Entity create(); void remove(Entity entity); void print() const; private: std::vector<Entity> m_entities{}; // sorted array (use std::set?) }; Entities::Entities(size_t size) { m_entities.reserve(size); } Entity Entities::create() { const auto it = std::adjacent_find(begin(m_entities), end(m_entities), [](Entity lhs, Entity rhs){ return (lhs+1 != rhs); }); if (it == end(m_entities)) { m_entities.push_back(m_entities.size()); return m_entities.back(); } else { const auto result = m_entities.insert(it+1, (*it)+1); return *result; } } void Entities::remove(Entity entity) { const auto it = std::find(begin(m_entities), end(m_entities), entity); if (it != end(m_entities)) { m_entities.erase(it); } } void Entities::print() const { for(auto i: m_entities) { std::cout << i << ' '; }; std::cout << std::endl; } /******* Component *******/ class Component { protected: Component(Entity entity); // disable instanciation of base Component public: Entity entity() const; private: Entity m_entity{}; }; Component::Component(Entity entity) : m_entity(entity) { } Entity Component::entity() const { return m_entity; } struct PositionComponent : public Component { int x{}; int y{}; }; struct StateComponent : public Component { enum class State { Waiting, Walking, Running, Dead }; State state { Waiting }; }; /******* Components *******/ template<class ConcretComponent> class Components { public: Components(size_t size = 1000); ConcretComponent& create(Entity entity); void remove(Entity entity); protected: // can add algos in derived classes std::vector<ConcretComponent> m_components{}; // not sorted array }; template<class ConcretComponent> Components::Components(size_t size) { m_components.reserve(size); } template<class ConcretComponent> ConcretComponent& Components::create(Entity entity) { m_components.push_back(ConcretComponent(entity)); } template<class ConcretComponent> void Components::remove(Entity entity) { std::remove_if(begin(m_components), end(m_components), [entity](const ConcretComponent &component){ return (component.entity() == entity); }); } /******* System *******/ class System { public: private: Components<T> m_components; } class System2 { public: System2(Components<T>& attachedComponents); private: Components<T>& m_components; } /******* Main *******/ int main() { // entities Entities entities; auto me = entities.create(); auto you = entities.create(); entities.print(); std::vector<Entity> badGuys; for(auto i=0; i<10; ++i) { badGuys.push_back(entities.create()); } entities.print(); entities.remove(you); // you're killed!!! entities.print(); you = entities.create(); // but you're a survivor entities.print(); }
Éléments de jeux appliqués à l'ECS
Comment implémenter dans un ECS…
Graphismes
camera, meshs, tiles
culling, quadtree/octree, scenegraph
inputs
éléments de gameplay
player, ennemis, terrain
collision, animation, physique
HUD
script
IA
state machine
L'ECS au delà des jeux
Que peut nous apprendre l'ECS sur le conception d'applications ?
Références
Bibliothèques existantes
- Feather Kit [SFML] : http://en.sfml-dev.org/forums/index.php?topic=14193.0 et http://featherkit.therocode.net/
- SEL [2D Game Engine, Lua] : http://forums.tigsource.com/index.php?topic=37684 et http://www.sel-engine.com/about/
Ressources
Conception objet
- SOLID blog emmanuel deloget
- code proprement, de philippe
- design pattern, en particulier visiteur
Généralités
- Entity component system (Wikipédia)
Autres langages
Blogs et forums
- StackExchange : http://gamedev.stackexchange.com/questions/23766/handling-scripted-and-native-components-in-a-component-based-entity-system?rq=1
-

Conclusion
Il ne faut pas se faire d'illusions : maintenant que vous avez lu cet article, vous ne savez toujours pas comment implémenter un ECS. Il va falloir vous lancer, faire des erreurs et recommencer pour réellement comprendre. Bref, acquérir de l'expérience.
Les questions de savoir comment organiser votre ECS, quels systèmes créer, que mettre dans chaque composant, sont des questions qui n'ont pas de réponses faciles et définitives. Cela dépend de votre expérience, de votre compréhension de l'ECS, de vos préférences personnelles.
Bon courage pour vos futurs jeux.
